A mental model for MCP tool development
May 16th, 2025
TLDR
Question: If you have local tools (local MCP Server), can you access them when using remote LLM via an API?
Answer: Yes! The SDK you use is really implementing a workflow of calls into the LLM on the other end of the wire - be it local or remote. The LLM will return a response indicating it wants to invoke a tool. The SDK (running locally) invokes the tool and calls the LLM again. This cycle can repeat itself, until the LLM returns a final output.
Level: This post is probably obvious to you if you have been creating agent systems, but if your experience with LLMs is limited to using the web interfaces (ChatGPT.com) or just within your programming IDE (Copilot in VSCode), then you'll learn something from this!
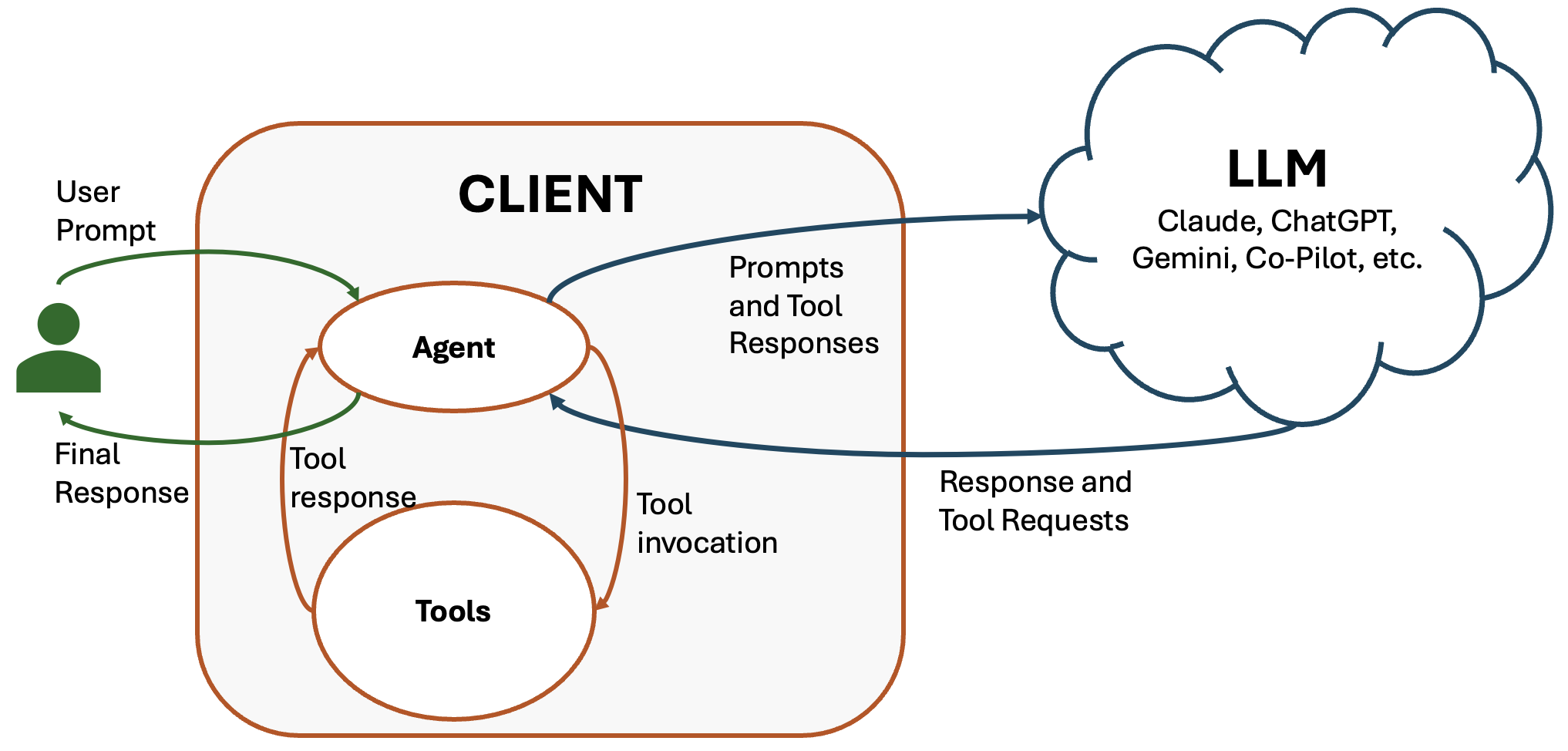 Relationship between local (client) agent loop and tools, and the cloud LLM provider
Relationship between local (client) agent loop and tools, and the cloud LLM provider
Background
When I first started exploring agent-based software architectures, and LLM APIs in general, there were a few things about the programming model that were kind of hazy to me, especially with MCP tools.
If I'm going to build an application that leverages an LLM, I have key decision: Is the LLM going to run locally on my own infrastructure, or am I going to use an API?
This post isn't about making this decision necessarily. There are great reasons to run LLM's locally, and ollama is a great place to get started with that. There's also very good reason not to, and a bunch of great API options - you know the main players - Anthropic, Google, OpenAI, and so on.
This post is about understanding how MCP fits into this decision. The Model Context Protocol (MCP) lets us hook our own tools (our own code, functions, URL endpoints, etc) into an LLM, allowing the LLM to use those tools when answering queries. MCP plays a key role in an Agentic Sofware Architecture, because it exposes your application to the LLM! It's a whole other post!
Here's the key question that I had when I started, and if you have the same question, this post will help:
If I use an API, where the LLM is not running locally on my machine, then how can the LLM access my tools via MCP? Can my tools be running locally, while the LLM isn't?
If you are wondering why someone would ask such a question, here's the scenario:
- You've got a web app, it's hosted on Digital Ocean. It's running on a nice cheap droplet.
- You want to leverage an LLM so your users interact by having a conversation.
- In order to answer questions effectively, the LLM needs to access API endpoints within your application.
This is Agentic Software Architecture - the functionality of the application is built of endpoints, function calls, apis - and the user interface is a conversational chat bot. The glue between is the LLM, it figures out what endpoints to call (the MCP tools) and mediates between the user and those endpoints to get things done.
In the above scenario, your inexpensive Digital Ocean droplet isn't going to be up to the task of running an LLM, so the decision is easy - you need to use an API.
The API (let's take OpenAI's API for now) is going to let you configure MCP tools, which the LLM running on OpenAI's infrastructure needs to be able to access. If your web application is hosted at https://aisauce.dev/tools, then that's easy - the MCP tool listing is globally available. But what about when you are developing?. What if the MCP server, the tools, are on your local computer. Can you still use a remote LLM? How would that work?
First Exploration
OpenAI has an example SDK that uses MCP. There are a few that are demonstrating local tools, and one that is setup to use remote-ish tools, over HTTP. The remote tool example actually models our exact question - it sets up a local HTTP server to expose the MCP tools, and calls into the LLM on OpenAI's infrastructure. The local HTTP server isn't accessible over the internet, the only way to call into it is clearly from code running on your own machine.
The example has two main files. server.py implmements the MCP server, which exposes three tools - one that adds two numbers, one that fetches the weather, and another that returns a secret word. Simple stuff, good example. I omitted the secret word and addition, and just kept the weather report for this example.
import requests
from mcp.server.fastmcp import FastMCP
# Create server
mcp = FastMCP("Weather Server")
@mcp.tool()
def get_current_weather(city: str) -> str:
print(f"[debug-server] get_current_weather({city})")
endpoint = "https://wttr.in"
response = requests.get(f"{endpoint}/{city}")
print("AI Sauce!")
return response.text
if __name__ == "__main__":
mcp.run(transport="sse")The other file, main.py implements the actual agent interaction. It creates an instance of the MCP server (take a look at the full code for those details), initializes a simple Agent class configured use a specific model and tools (the MCP tools), and a system prompt. The agent configuration is also set up to instruct the LLM to try to use the tools for relevant tasks. Here's a snipped from the example:
agent = Agent(
name="Assistant",
instructions="Use the tools to answer the questions.",
mcp_servers=[mcp_server],
model_settings=ModelSettings(tool_choice="required"),
)After configuring the Agent, the script invokes it with a simple prompt. The LLM returns a response and it's printed to the console.
# Run the `get_weather` tool
message = "What is the weather in Tokyo?"
print(f"\n\nRunning: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)Take some time to look at the complete code. After installing the necessary dependencies, and configuring the OpenAI API Key, you can give it a run.
% python3 main.py
Starting SSE server at http://localhost:8000/sse ...
INFO: Started server process [21939]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
SSE server started. Running example...
INFO: 127.0.0.1:53310 - "GET /sse HTTP/1.1" 200 OK
INFO: 127.0.0.1:53312 - "POST /messages/?session_id=1c5f61554c5446eaabb3498ceedc736c HTTP/1.1" 202 Accepted
View trace: https://platform.openai.com/traces/trace?trace_id=trace_90cbd98d8e4d4859af36c3ccff8616f0
Running: What is the weather in Tokyo?
INFO: 127.0.0.1:53312 - "POST /messages/?session_id=1c5f61554c5446eaabb3498ceedc736c HTTP/1.1" 202 Accepted
Processing request of type ListToolsRequest
INFO: 127.0.0.1:53312 - "POST /messages/?session_id=1c5f61554c5446eaabb3498ceedc736c HTTP/1.1" 202 Accepted
Processing request of type CallToolRequest
[debug-server] get_current_weather(Tokyo)
The current weather in Tokyo is moderate rain with a temperature of 64°F. The wind is blowing from the north-northwest at 20 mph, and the visibility is about 4 miles with 0.2 inches of precipitation.So we certainly have an answer - we've managed to have the LLM use the local tool in it's response! But wait a minute... how did this actually work? Here's the Python code that invokes the LLM running on OpenAI's infrastructure again:
agent = Agent(
name="Assistant",
instructions="Use the tools to answer the questions.",
mcp_servers=[mcp_server],
model_settings=ModelSettings(tool_choice="required"),
)
# Use the `add` tool to add two numbers
message = "What is the weather in Tokyo?"
print(f"\n\nRunning: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)The LLM understood the prompt, and used the tool we defined in mcp_server. But if the LLM is running in the cloud, and the tools are running on my machine, how did it work? Is the LLM actually synthesizing the results of the tools? Is there a conversation between the LLM and the tools?
I changed the prompt just to convince myself that the LLM is absolutely calling the tool and processing the tool's output:
# Run the `get_weather` tool
message = "What's the weather in Tokyo? Answer in elaborate text, with lots of intense emotion, so much so it's kind of funny. Every sentance ends with an exclamation mark."
print(f"\n\nRunning: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)Yep.. the LLM is absolutely getting the results from the tool and synthesizing a response as part of a coherant (and entertaining) conversation:
Oh my goodness, folks! Grab your umbrellas and brace yourselves because Tokyo is experiencing an intense bout of moderate rain! Can you believe it?! It's like the heavens have decided to open up and shower us with their powerful, watery embrace! The temperature is a brisk 64°F, just cool enough to make you crave a cozy sweater as the raindrops dance around you with a rhythm only Mother Nature could orchestrate!
And let me tell you, the wind is nothing short of dramatic! Gusting in from the northwest at a formidable 20 mph, it's as if the wind itself is trying to join in on the wild weather party! The visibility is a mysterious 4 miles, shrouded in mist and moisture, making everything feel delightfully enigmatic!
Don't even get me started on the rain accumulation—it's a daring 0.2 inches, bringing that delightful sound of pitter-patter as if the skies are composing a symphony just for us! This is weather with capital letters, folks! Pure, unfiltered, exhilarating weather that evokes every emotion under the sun—or should I say, under the clouds!
So bundle up, stay dry, and revel in today's theatrics as Tokyo transforms into a stage for nature's grand performance! Weather so amazing, it's almost too much to handle!
Never gets old :)
OK, so now we have a pretty solid picture of the architecture being used by the OpenAI SDK. After the LLM is invoked, it has the ability to call my machine back, via the SDK (since my local machine isn't accessible over standard HTTP or anything). The SDK is the glue that allows the LLM in the cloud to talk to the MCP servers running on my machine.
Diving into the SDK
Let's prove our hypothesis by inspecting the SDK. The example code used Runner to invoke the LLM, which is in the agents/run.py script. It's outlined nicely in the comments, the Runner class is really just a workflow, where an agent (LLM) is invoked in a loop, until a final output has been returned.
Here's the relevant comment, at the top of the Runner.run code file:
Run a workflow starting at the given agent. The agent will run in a loop until a final output is generated. The loop runs like so:
- The agent is invoked with the given input.
- If there is a final output (i.e. the agent produces something of type
agent.output_type, the loop terminates.- If there's a handoff, we run the loop again, with the new agent.
- Else, we run tool calls (if any), and re-run the loop.
So there we have it, the agent is returning results of specific types, including responses that ask for tool invocation. We aren't calling the LLM once, we are having a conversation with it.
If you are new to LLM integration, then the above point is super important. When you invoke remote LLM models you are likely paying money for each token in your input prompt, context, and in the output. When you start considering that a single input from the user (a prompt) can actually result in a chain of LLM invocations, which potentially are creating intermediate prompts using the output of tools, you can start to see clearly how expensive things can get! It's not just one interaction, it's potentially many!
Intermediate LLM outputs?
What are these outputs from the LLM? The comments talk about three possibilities - a final output, a handoff, and a tool call. I'm going to save handoffs for another post. It's a pretty simple concept though, an "agent" is an LLM with a specific system prompt and context (and of course, perhaps a specifically trained or tuned model). For some tasks, you might want to have specialized agents, and you may need an managing agent to triage the user's input and direct it to the appropriate agent. That's a handoff - the response of one LLM is to hand off to another agent it's been made aware of. It turns out tools are the same thing actually, they are essentially implemented just like a handoff.
The Runner API allows you to configure a series of handoff agents and a series of tools, all of which are included in the system prompt being used when the initial agent is invoked after user input. It's all here.
Conclusion
The original question this post is answering is whether or not a remote LLM invocation can take advantage of a local tool. Experienced software developers (but new to AI) wonder about this, becuase they intuitively understand that the LLM they are calling into executes on a remote infrastructure, and that the LLM is essentially a black box.
The key concept however is that there's a difference between an agent and an LLM, and these terms often get used interchangeably - and that's a shame! An LLM is a natural language processing facility, with an uncanny ability to look very much like it's truly understanding the prompt. It's awesome, but it's just a text completer. An LLM doesn't have memory - it's stateless. An agent is software that wraps an LLM in a stateful system - where an LLM can be asked a series of questions, with retained information (resending information in subsequent prompts), and tool execution.
Agents, when we build our applications, execute on the host machine. When an agent needs to invoke an LLM, it can invoke a local LLM or a remote one just the same. Regardless, the agent code is the one that receives an LLM result indicating a tool execution, and that's exactly what allows the agent to invoke local tools, on the host!
Relationship between local (client) agent loop and tools, and the cloud LLM provider
The key insight is that the LLM is not having a conversation directly with MCP tools, it's the agent that is mediating between the LLM and the tools.
Some more of my work...

Ramapo College
Professor of Computer Science, Chair of Computer Science and Cybersecurity, Director of MS in Computer Science, Data Science, Applied Mathematics

Frees Consulting and Development LLC
My consultancy - Your ideas into real working solutions and product: building MVPs, modernizing legacy systems and integrating AI and automation into your workflows.

Node.js C++ Integration
My work on Node.js and C++ Integration, a blog and e-book. Native addons, asynchronous processing, high performance cross-platform deployment.

Foundations of Web Development
For students and professionals - full-stack guide to web development focused on core architectural concepts and lasting understanding of how the web works
The views and opinions expressed in this blog are solely my own and do not represent those of Ramapo College or any other organization with which I am affiliated.